

Nvidia’s New Chip Shows Its Muscle in AI Tests

It is time for the “Olympics of machine learning” again, and if you are worn out of seeing Nvidia at the top rated of the podium about and over, way too poor. At the very least this time, the GPU powerhouse place a new contender into the mix, its Hopper GPU, which sent as a great deal as 4.5 moments the performance of its predecessor and is due out in a issue of months. But Hopper was not on your own in earning it to the podium at MLPerf Inferencing v2.1. Programs dependent on Qualcomm’s AI 100 also built a very good exhibiting, and there were other new chips, new forms of neural networks, and even new, much more sensible approaches of tests them.
In advance of I go on, enable me repeat the canned reply to “What the heck is MLPerf?”
MLPerf is a set of benchmarks agreed on by customers of the field group MLCommons. It is the to start with try to deliver apples-to-apples comparisons of how fantastic pcs are at training and executing (inferencing) neural networks. In MLPerf’s inferencing benchmarks, programs built up of combos of CPUs and GPUs or other accelerator chips are examined on up to 6 neural networks that execute a wide range of typical functions—image classification, object detection, speech recognition, 3D healthcare imaging, natural-language processing, and advice. The networks experienced previously been experienced on a conventional established of knowledge and had to make predictions about facts they experienced not been exposed to ahead of.
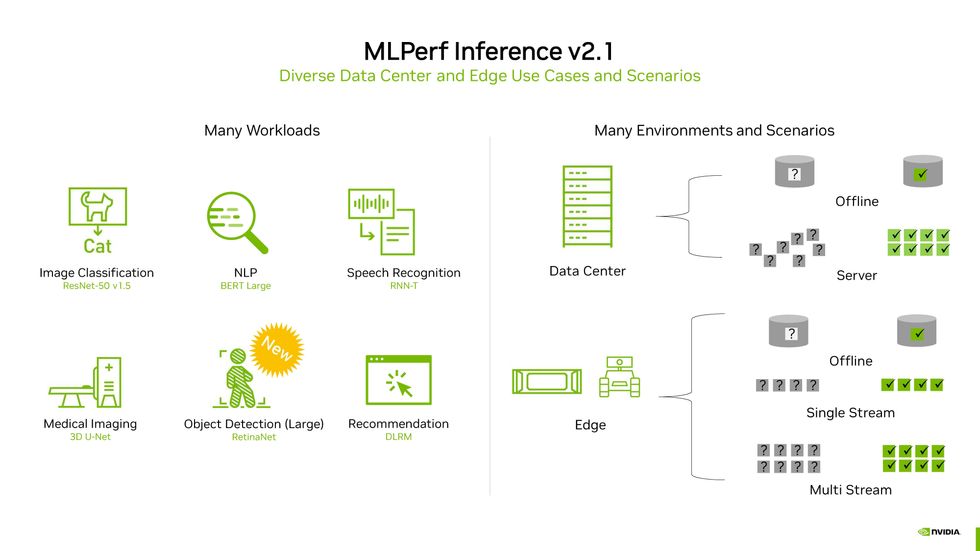
This slide from Nvidia sums up the total MLPerf exertion. 6 benchmarks [left] are examined on two sorts of personal computers (facts center and edge) in a wide variety of disorders [right].Nvidia
Analyzed personal computers are categorized as intended for info centers or “the edge.” Commercially available facts-centre-centered devices were being examined less than two conditions—a simulation of real data-center activity the place queries arrive in bursts and “offline” exercise where by all the knowledge is out there at at the time. Personal computers meant to perform on-website alternatively of in the details center—what MLPerf phone calls the edge, mainly because they’re situated at the edge of the network—were measured in the offline condition as if they have been obtaining a solitary stream of info, these kinds of as from a safety camera and as if they had to tackle numerous streams of information, the way a car or truck with various cameras and sensors would. In addition to tests raw effectiveness, desktops could also contend on efficiency.
The contest was additional divided into a “closed” category, where all people had to operate the very same “mathematically equivalent” neural networks and fulfill the similar accuracy measures, and an “open” group, where by companies could exhibit off how modifications to the regular neural networks make their units perform superior. In the contest with the most potent computer systems under the most stringent problems, the closed information-heart group, computers with AI accelerator chips from four companies competed: Biren, Nvidia, Qualcomm, and Sapeon. (Intel created two entries without the need of any accelerators, to reveal what its CPUs could do on their possess.)
Whilst numerous techniques were examined on the entire suite of neural networks, most benefits were submitted for picture recognition, with the organic-language processor BERT (small for Bidirectional Encoder Representations from Transformers) a near second, building those people categories the easiest to evaluate. Various Nvidia-GPU-based programs ended up analyzed on the complete suite of benchmarks, but doing even just one benchmark can get much more than a thirty day period of operate, engineers associated say.
On the image-recognition demo, startup Biren’s new chip, the BR104, executed nicely. An eight-accelerator laptop or computer built with the company’s associate, Inspur, blasted through 424,660 samples for each second, the fourth-speediest system examined, at the rear of a Qualcomm Cloud AI 100-centered machine with 18 accelerators, and two Nvidia A100-centered R&D programs from Nettrix and H3C with 20 accelerators just about every.
But Biren actually showed its power on all-natural-language processing, beating all the other 4-accelerator programs by at minimum 33 p.c on the maximum-precision variation of BERT and by even greater margins among 8-accelerator programs.
An Intel procedure based on two before long-to-be-introduced Xeon Sapphire Rapids CPUs without the need of the help of any accelerators was another standout, edging out a machine working with two recent-generation Xeons in mix with an accelerator. The variation is partly down to Sapphire Rapids’ Innovative Matrix Extensions, an accelerator worked into each and every of the CPU’s cores.
Sapeon offered two units with unique variations of their Sapeon X220 accelerator, tests them only on graphic recognition. Both of those handily conquer the other solitary-accelerator computers at this, with the exception of Nvidia’s Hopper, which obtained by 6 situations as a lot perform.
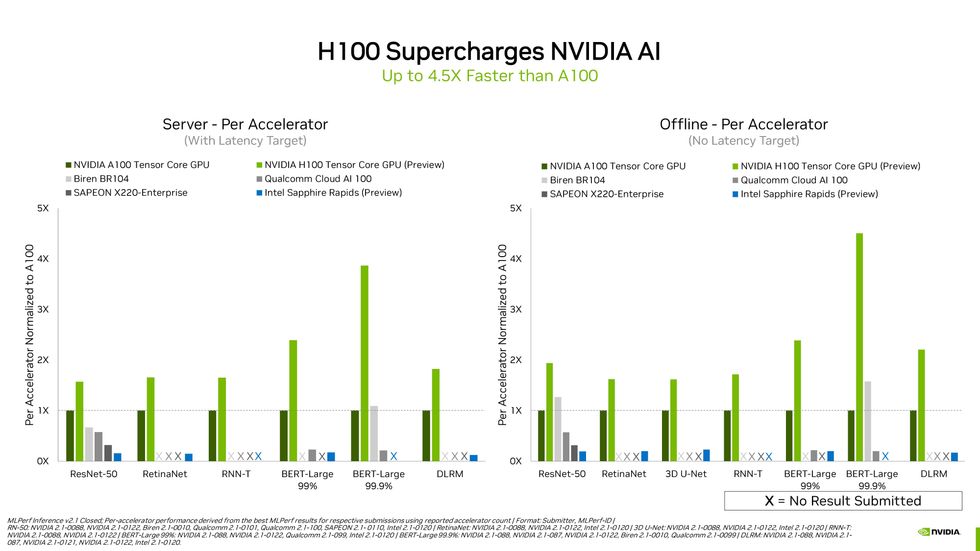
Computers with numerous GPUs or other AI accelerators typically operate faster than these with a single accelerator. But on a per-accelerator foundation, Nvidia’s impending H100 fairly significantly crushed it.Nvidia
In reality, among techniques with the very same configuration, Nvidia’s Hopper topped every single class. In contrast to its predecessor, the A100 GPU, Hopper was at the very least 1.5 periods and up to 4.5 situations as rapidly on a for every-accelerator basis, relying on the neural network beneath exam. “H100 arrived in and really brought the thunder,” says Dave Salvator, Nvidia’s director of item advertising for accelerated cloud computing. “Our engineers knocked it out of the park.”
Hopper’s not-magic formula-at-all sauce is a procedure known as the transformer engine. Transformers are a class of neural networks that incorporate the purely natural-language processor in the MLPerf inferencing benchmarks, BERT. The transformer motor is intended to pace inferencing and education by altering the precision of the numbers computed in every layer of the neural network, working with the minimum required to access an exact final result. This features computing with a modified model of 8-bit floating-place figures. (Here’s a a lot more total clarification of minimized-precision equipment studying.)
Because these benefits are a very first try at the MLPerf benchmarks, Salvator says to expect the hole amongst H100 and A100 to widen, as engineers discover how to get the most out of the new chips. There is great precedence for that. By way of application and other enhancements, engineers have been able to velocity up A100 devices repeatedly given that its introduction in May possibly 2020.
Salvator suggests to assume H100 success for MLPerf’s efficiency benchmarks in upcoming, but for now the business is centered on viewing what sort of efficiency they can get out of the new chip.
Performance
On the effectiveness front, Qualcomm Cloud AI 100-centered machines did themselves happy, but this was in a a great deal smaller sized area than the overall performance contest. (MLPerf representatives pressured that computer systems are configured in a different way for the performance checks than for the functionality checks, so it is only truthful to examine the overall performance of methods configured to the similar goal.) On the offline impression-recognition benchmark for details-heart techniques, Qualcomm took the major three spots in phrases of the range of visuals they could understand for every joule expended. The contest for effectiveness on BERT was a great deal nearer. Qualcomm took to the major location for the 99-percent-precision edition, but it misplaced out to an Nvidia A100 technique at the 99.99-percent-precision undertaking. In each conditions the race was near.
The circumstance was identical for impression recognition for edge units, with Qualcomm taking practically all the top rated spots by working with streams of facts in much less than a millisecond in most scenarios and usually making use of less than .1 joules to do it. Nvidia’s Orin chip, due out in 6 months, came closest to matching the Qualcomm results. Once more, Nvidia was superior with BERT, working with fewer strength, even though it even now couldn’t match Qualcomm’s pace.
Sparsity
There was a ton going on in the “open” division of MLPerf, but a single of the extra exciting final results was how providers have been showing how properly and effectively “sparse” networks perform. These consider a neural community and prune it down, getting rid of nodes that add very little or absolutely nothing toward making a consequence. The much smaller sized network can then, in theory, run quicker and far more proficiently though working with significantly less compute and memory sources.
For illustration, startup Moffett AI confirmed results for a few desktops utilizing its Antoum accelerator architecture for sparse networks. Moffett examined the techniques, which are meant for facts-center use on picture recognition and all-natural-language processing. At picture recognition, the company’s commercially available process managed 31,678 samples per second, and its coming chip hit 95,784 samples for every 2nd. For reference, the H100 hit 95,784 samples per second, but the Nvidia equipment was doing work on the comprehensive neural network and satisfied a larger accuracy target.
Another sparsity-concentrated agency, Neural Magic, confirmed off software package that applies sparsity algorithms to neural networks so that they operate a lot quicker on commodity CPUs. Its algorithms reduced the sizing of a version of BERT from 1.3 gigabytes to about 10 megabytes and boosted throughput from about 10 samples for each 2nd to 1,000, the corporation states.
And ultimately, Tel Aviv-based mostly Deci utilized computer software it phone calls Automatic Neural Architecture Construction technologies (AutoNAC) to develop a version of BERT optimized to run on an AMD CPU. The resulting community sped throughput far more than sixfold working with a design that was just one-3rd the size of the reference neural community.
And A lot more
With much more than 7,400 measurements across a host of types, there is a lot extra to unpack. Really feel free of charge to acquire a seem yourself at MLCommons.